Tool Use
Graham Neubig
What are Tools
- External to the LM (part of environment)
- Function interface (callable with inputs/outputs)
- Programmatic (executable in corresponding environments)
Tool Categories and Applications
Perception
Collect information
Action
Change environment
Computation
Complex calculations
| Category | Example Tools | Use Cases |
|---|---|---|
| Knowledge | search_engine(), sql_executor() |
Web search, database queries |
| Computation | calculator(), python_interpreter() |
Math, data analysis |
| World | get_weather(), calendar.fetch_events() |
Real-time information |
| Modalities | visual_qa(), spotify.play_music() |
Multimedia processing |
The Basic Tool Use Paradigm
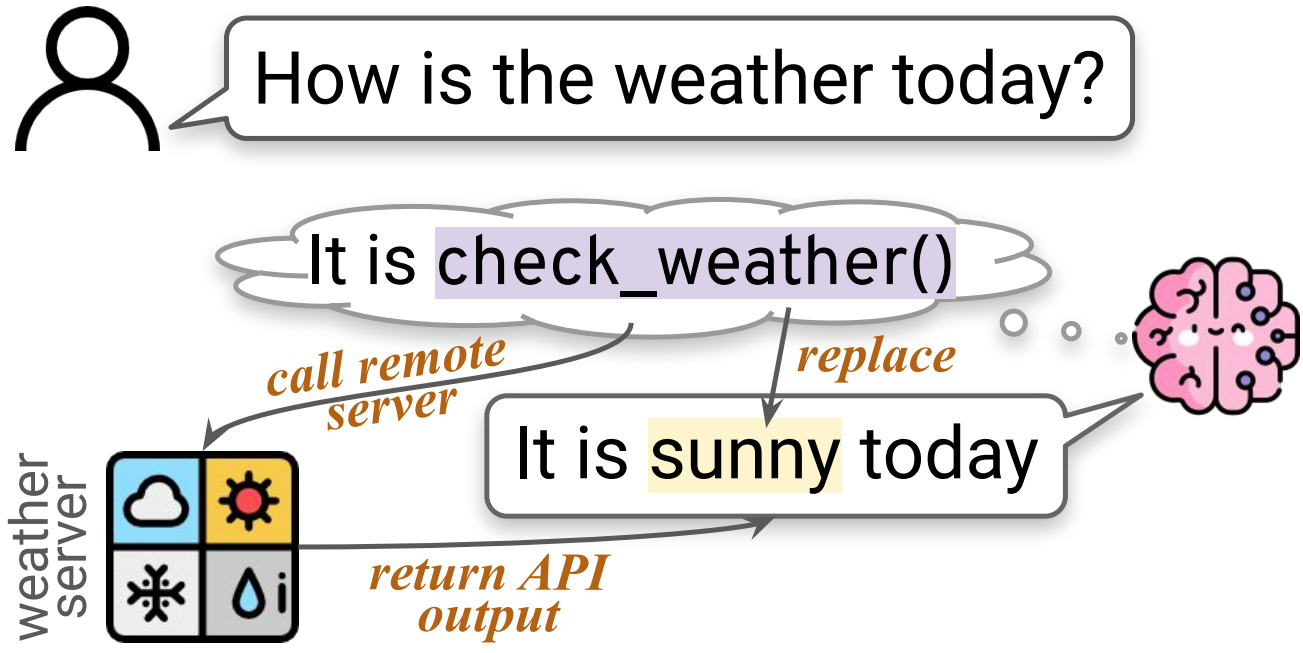
Example: WebGPT (Nakano+ 2021)
Motivation: LMs lack access to current information
Solution: Text-based web browsing as a tool
- Text-based interface: Search, click, scroll, quote
- Citation collection: Gather references while browsing
- Human feedback: RLHF on browsing and answer quality
WebGPT: Training Process
- Behavior cloning: Learn from human browsing demonstrations
- Reward modeling: Train model to predict human preferences
- Reinforcement learning: Optimize for reward model preferred answers
WebGPT: Results
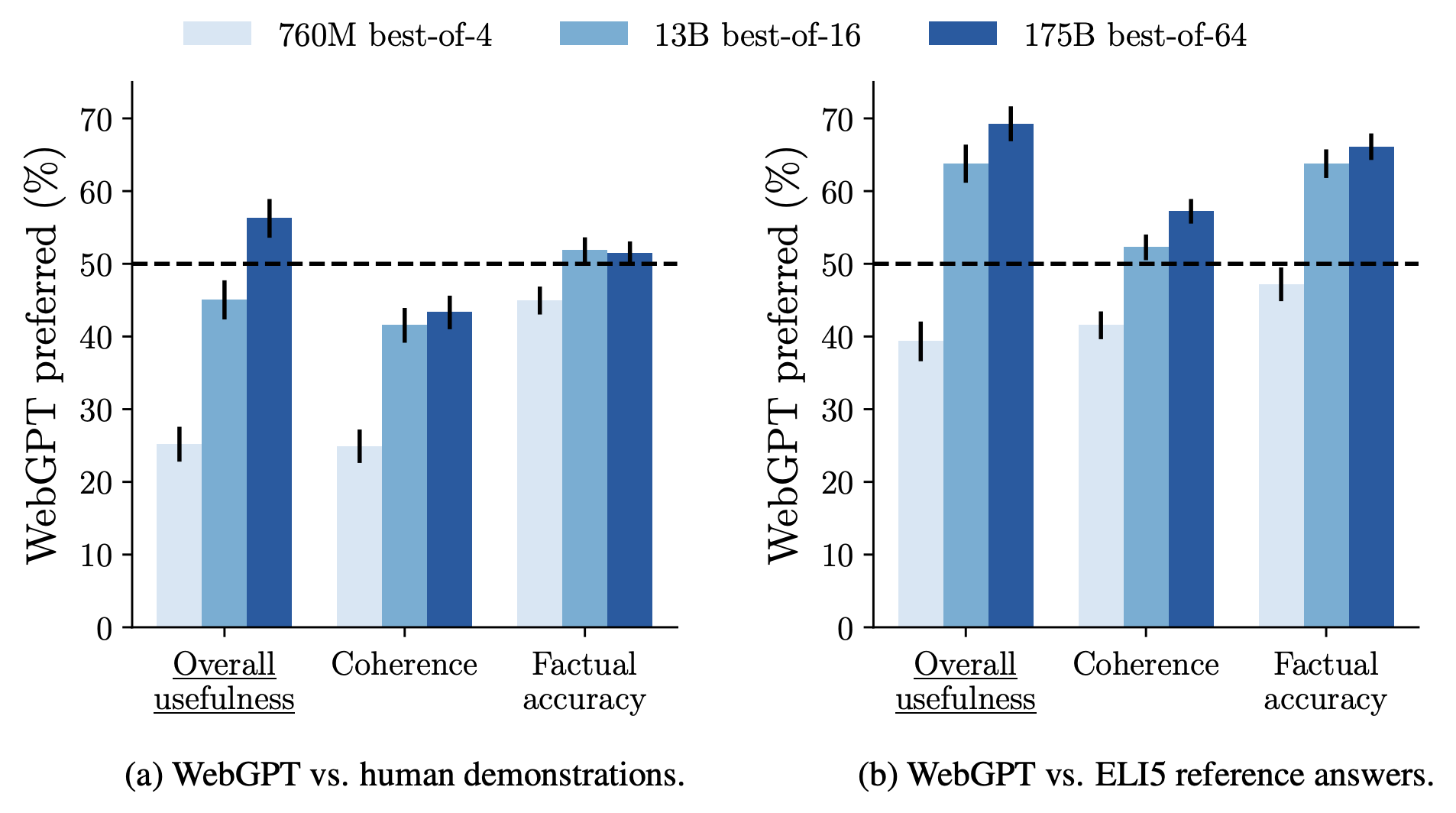
- 56% preferred over human demonstrators
- 69% preferred over Reddit’s highest-voted answers
- Verifiable answers: Citations enable fact-checking
ToolFormer: Learning to Use Tools (Schick+ 2023)
Motivation: Previous approaches require manual annotation
- Hand-crafting tool usage examples is expensive
- Models need to learn when to use tools, not just how
- Solution: Self-supervised learning from unlabeled text
ToolFormer: Key Innovation
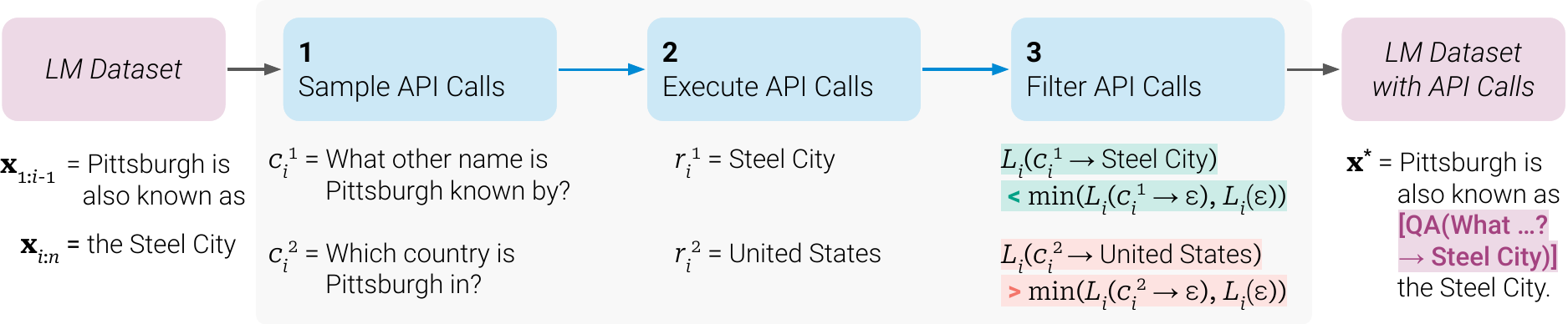
Core Innovation: Models learn tool use without human supervision
- Self-annotation: Generate potential tool calls automatically
- Filtering: Keep only calls that improve prediction
- Fine-tuning: Train on successful tool usage patterns
ToolFormer: Results and Limitations
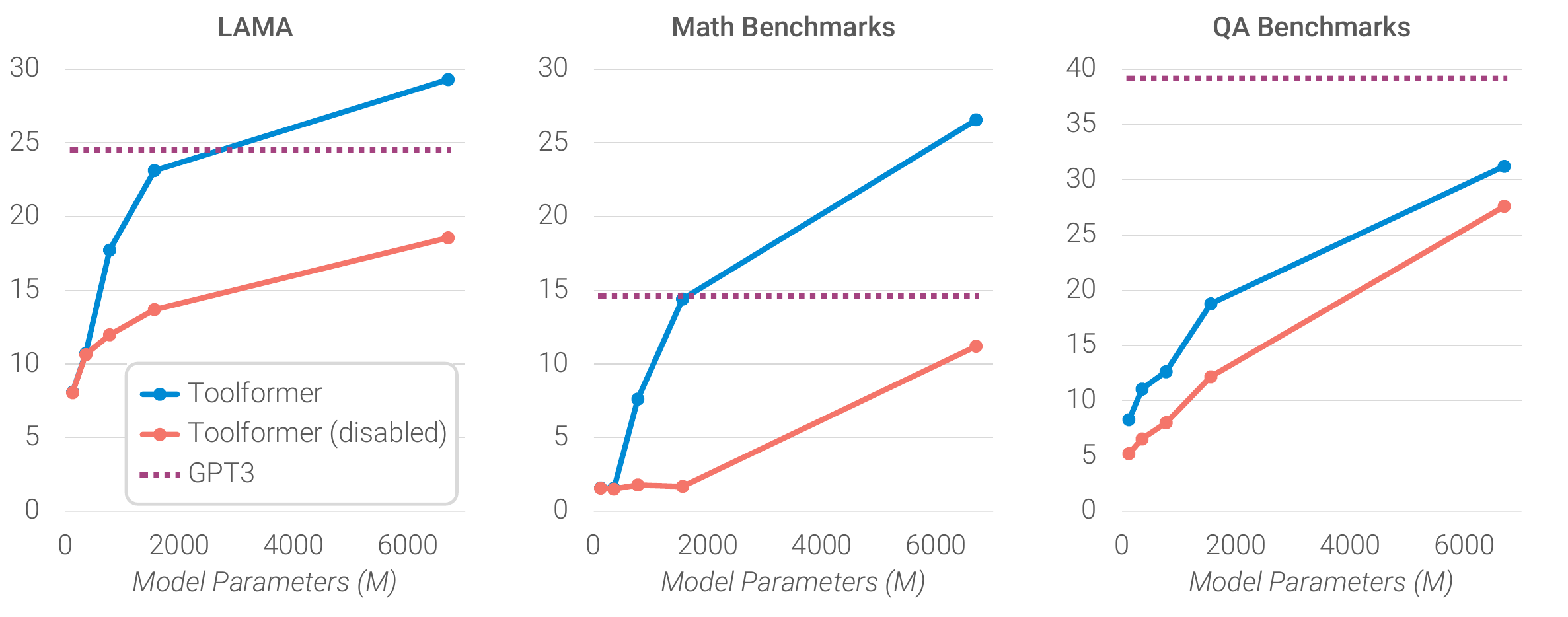
- Results: Improvements on math, QA, and factual tasks
- Limitations: Requires pre-existing tool APIs
Modern Function Calling: JSON Schema
Standardized format across major LLM providers:
{
"name": "get_weather",
"description": "Get current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City name"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
Function Calling Response
LM generates structured function calls:
{
"role": "assistant",
"content": null,
"function_call": {
"name": "get_weather",
"arguments": "{\"location\": \"Boston\", \"unit\": \"celsius\"}"
}
}
Benefits: Type safety, validation, consistent parsing
Parallel Function Calling
Execute multiple tools simultaneously:
{
"role": "assistant",
"tool_calls": [
{
"id": "call_1", "type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"location\": \"Boston\"}"
}
},
{
"id": "call_2", "type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"location\": \"New York\"}"
}
}
]
}
Model Context Protocol (MCP)
Standardized protocol for connecting AI applications to external systems
- A standardized format for defining new sets of tools
- Adopts client-server protocol, each tool set is a server
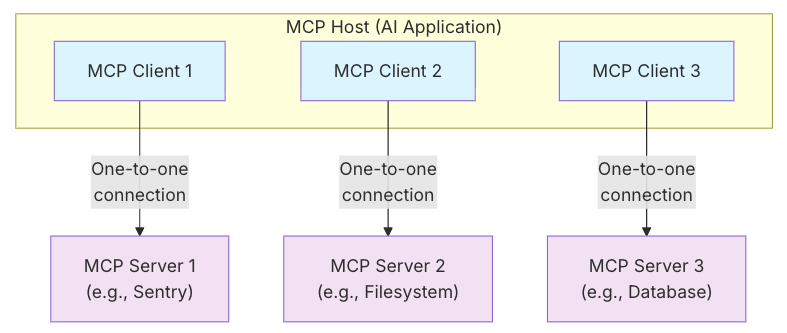
MCP Registry and Ecosystem
- Tens of thousands of MCPs exist
- Central registry: registry.modelcontextprotocol.io
- Can include sub-registries (e.g. for individual companies)
FastMCP: Rapid MCP Development
FastMCP: Python framework for building MCP servers
from fastmcp import FastMCP
mcp = FastMCP("Demo Server")
@mcp.tool
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
@mcp.tool
async def remember(contents: list[str]) -> str:
"""Store memories with vector embeddings"""
# Complex async operations, database access
return await store_memories(contents)
Key Features: Enterprise auth (Google, GitHub, Azure), deployment tools, server composition, OpenAPI generation
Program-Aided Language Models (PAL; Gao+ 2022)
Motivation: LMs struggle with multi-step arithmetic reasoning
- Chain-of-thought helps but still makes calculation errors
- Natural language arithmetic is error-prone
- Solution: Use code execution as a “calculator tool”
PAL: Key Innovation

PAL: Experimental Results
Problem solve rate (%) on mathematical reasoning datasets:
| Method | GSM8K | SVAMP | ASDIV | MAWPS-SingleEq | MAWPS-AddSub |
|---|---|---|---|---|---|
| Direct (Codex) | 19.7 | 17.1 | 4.1 | 58.8 | 72.0 |
| CoT (Codex) | 65.6 | 74.8 | 56.9 | 79.0 | 86.0 |
| PAL (Codex) | 72.0 | 79.4 | 76.9 | 79.6 | 92.5 |
Key Findings:
- PAL achieves state-of-the-art performance across all mathematical reasoning tasks
- 15% absolute improvement over CoT on GSM8K (72.0% vs 65.6%)
- Consistent gains across diverse problem types and complexities
Sandboxed Code Execution
Problem: LLM-generated code execution poses security risks
- Plain LLM errors: Unintentional harmful commands
- Supply chain attacks: Compromised or untrusted models
- Prompt injection: Malicious instructions from web content
- Public exploitation: Adversarial inputs to accessible agents
Solution: Multiple sandboxing approaches with different isolation levels
Sandboxing Approaches
Local AST-based Interpreter (smolagents LocalPythonExecutor):
- Custom Python interpreter using AST parsing
- What’s sandboxed: Import restrictions, dangerous functions, dunder methods
- What’s not: Still runs in same process, memory access possible
Container-based Isolation (Docker, E2B):
- What’s sandboxed: Complete OS-level isolation, network restrictions
- What’s not: Resource consumption within container limits
WebAssembly Execution (Pyodide + Deno):
- What’s sandboxed: Memory isolation, no direct system access
- What’s not: Limited Python ecosystem, performance overhead
AST-based Implementation Details
Allowed built-ins: Only safe modules like math, datetime, collections
BASE_BUILTIN_MODULES = [
"collections", "datetime", "itertools", "math",
"queue", "random", "re", "statistics", "time"
]
Blocked operations:
DANGEROUS_MODULES = ["os", "subprocess", "socket", "sys"]
DANGEROUS_FUNCTIONS = ["eval", "exec", "compile", "__import__"]
# Dunder method protection
if name.startswith("__") and name.endswith("__"):
raise InterpreterError(f"Forbidden access: {name}")
Operation limits: Max 10M operations, 1M while loop iterations
Tools in Programs
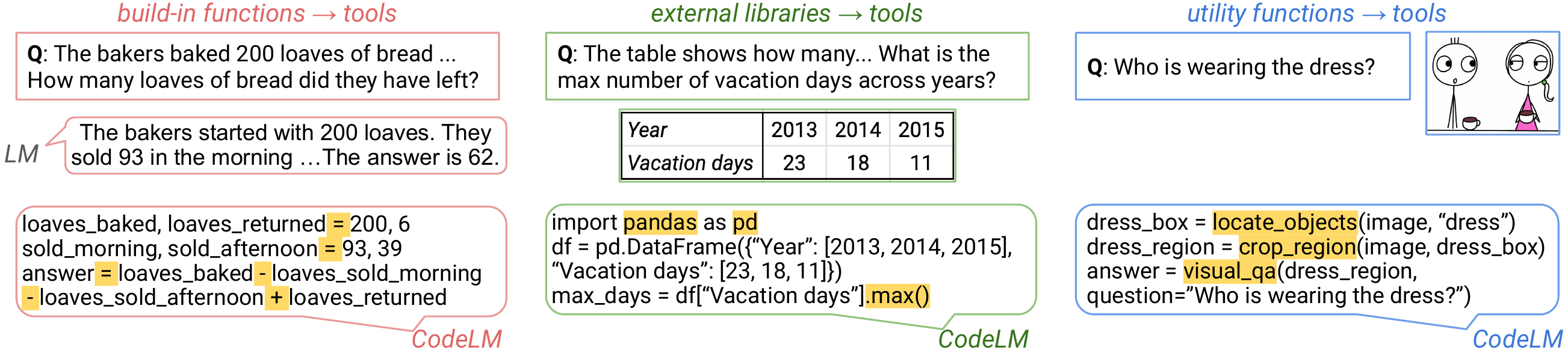
- Built-in functions: Core language primitives
- External libraries: Third-party packages (pandas, matplotlib)
- Utility functions: Task-specific, expert-crafted tools
Gorilla: Large Language Model Connected with Massive APIs (Patil+ 2023)
Motivation: Real-world APIs are complex and numerous
- Thousands of APIs with different interfaces
- Documentation is often incomplete or unclear
- Generic models struggle with API-specific syntax
- Solution: Specialized training on API documentation
Gorilla: Key Innovation
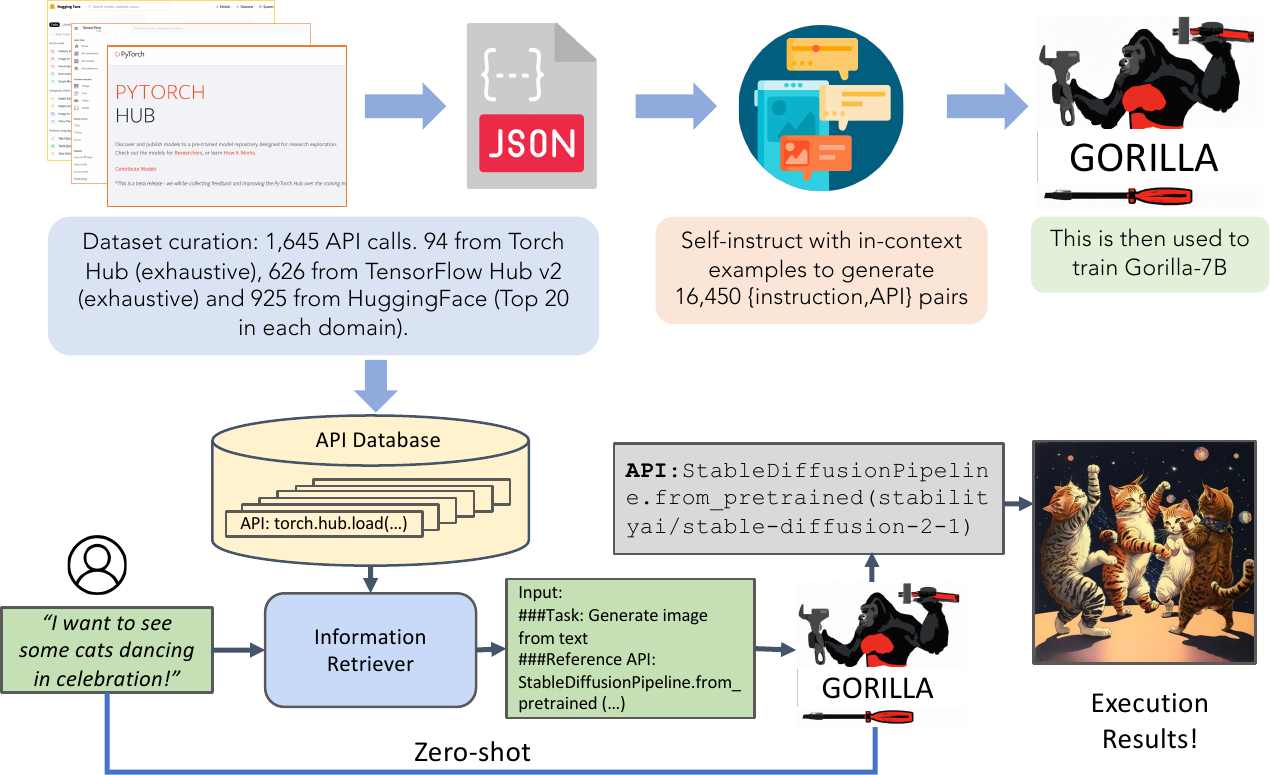
- Large-scale dataset: API documentation + usage examples
- Multi-domain: TensorFlow, PyTorch, HuggingFace APIs
- Retrieval-aware: Can use documentation at inference time
Gorilla: Training and Results
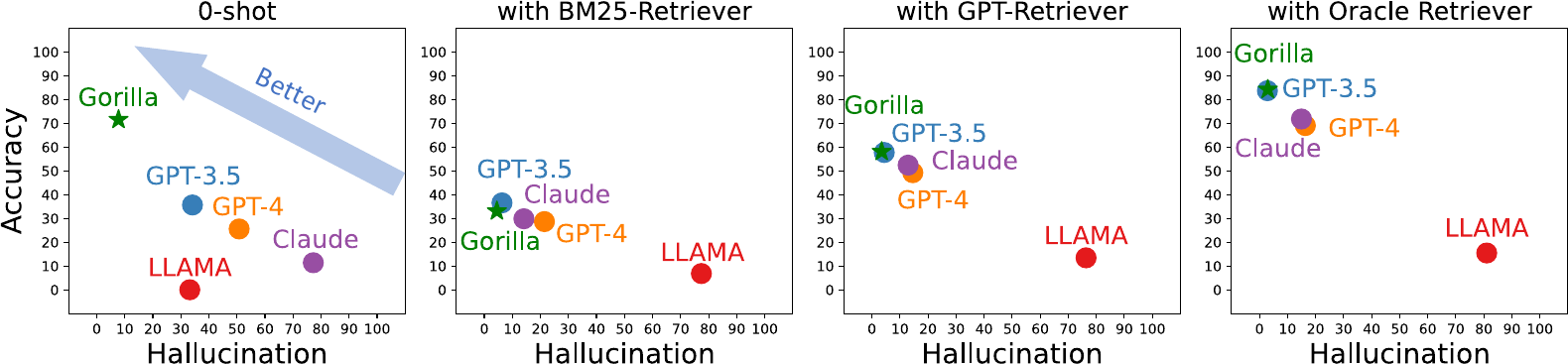
- Outperforms GPT-4 on API benchmarks
- Better API selection and parameter usage
- Reduced hallucination of non-existent APIs
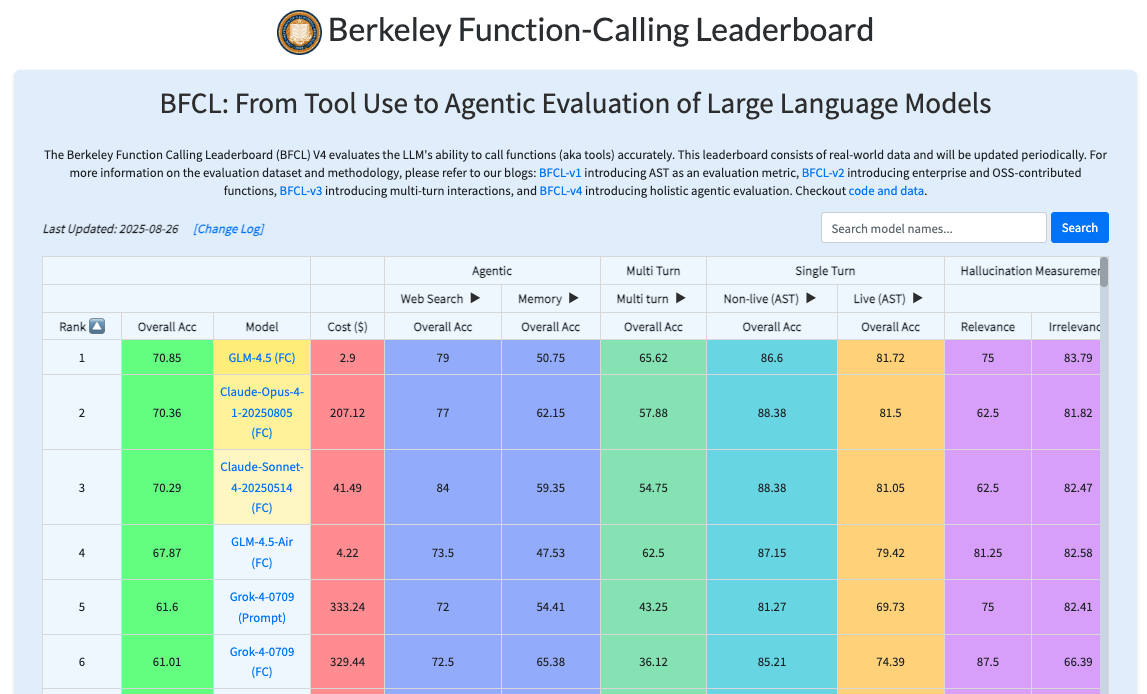
Berkeley Function Calling Leaderboard (BFCL)
ToolRL: Reasoning for Tools
- SFT struggles with complex tool use scenarios
- Comprehensive study on reward design for tool use in RL
ToolRL: Reward Design Framework
Format Reward (checks structural compliance):
Correctness Reward (evaluates tool call accuracy):
- Tool Name Matching: \(r_{\text{name}} = \frac{|N_G \cap N_P|}{|N_G \cup N_P|}\)
- Parameter Name Matching: \(r_{\text{param}} = \sum_{G_j \in G} \frac{|\text{keys}(P_G) \cap \text{keys}(P_P)|}{|\text{keys}(P_G) \cup \text{keys}(P_P)|}\)
- Parameter Content Matching: \(r_{\text{value}} = \sum_{G_j \in G} \sum_{k \in \text{keys}(G_j)} \mathbf{1}[P_G[k] = P_P[k]]\)
Final Reward: \(\mathcal{R}_{\text{final}} = \mathcal{R}_{\text{format}} + \mathcal{R}_{\text{correct}} \in [-3, 4]\)
ToolRL: Training Results
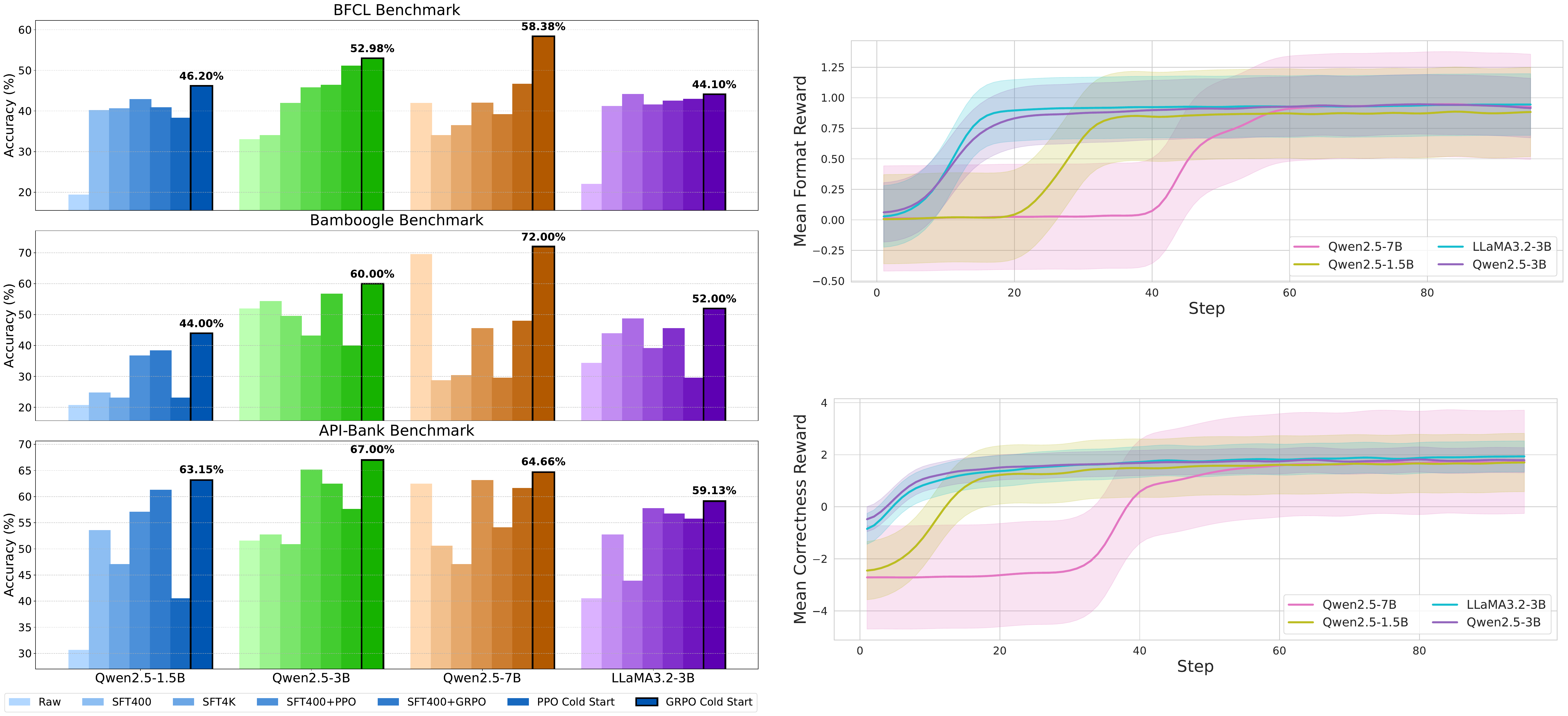
- GRPO Cold Start consistently achieves highest performance
- Rapid reward increase during training shows effective learning
- Stable convergence across different model sizes
ToRL: Tools for Reasoning
- Leverages external tools within LM reasoning
- RL directly from base models
- Code interpreters in RL training loop
ToRL: Performance
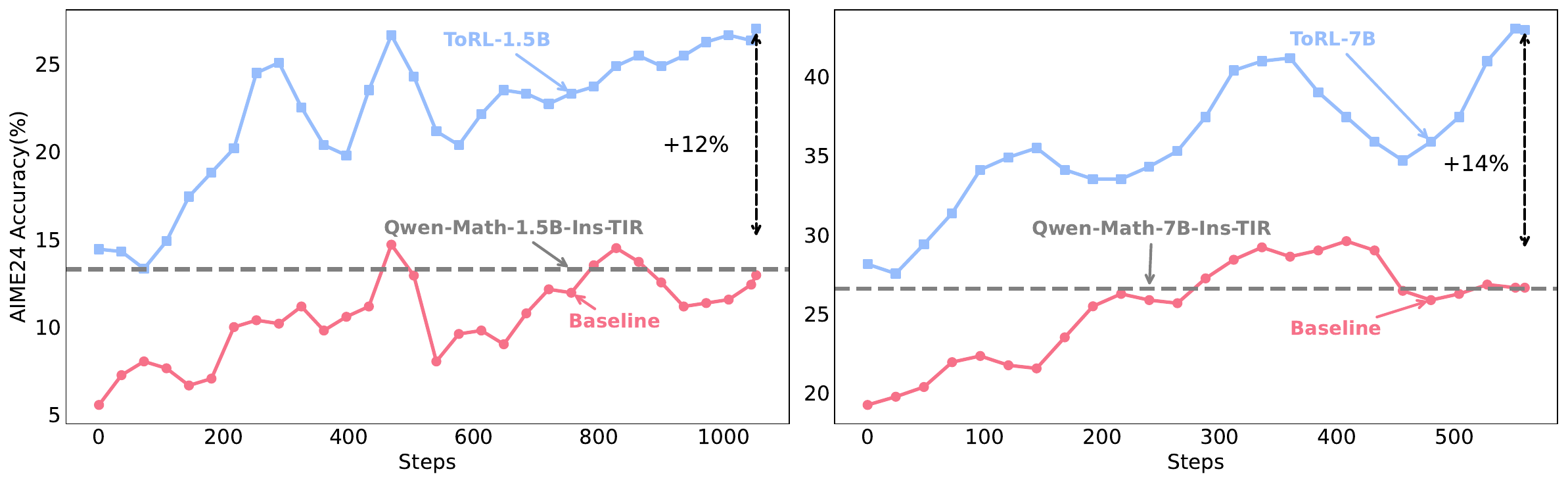
- 43.3% accuracy on AIME24 w/ 7B model
- +14% improvement over RL without tools
- +17% improvement over best existing TIR model
- Matches 32B models trained with RL
ToRL vs ToolRL: Key Contrasts
ToolRL: Reasoning FOR Tools
- Focus: Better tool selection through RL
- Method: Reward design for tool use tasks
- Goal: Improve how models choose and use tools
- Training: RL to optimize tool calling behavior
- Evaluation: Tool use benchmarks (BFCL, API-Bank)
ToRL: Tools FOR Reasoning
- Focus: Tools enhance RL reasoning process
- Method: Integrate code interpreters in RL training
- Goal: Improve mathematical reasoning with tools
- Training: RL with computational tools in the loop
- Evaluation: Mathematical benchmarks (AIME, MATH)
Tool Robustness: Benchmarking Failures in TaLMs
Problem: Most tool benchmarks assume perfect conditions
Reality: Under-specified queries and unavailable tools cause failures
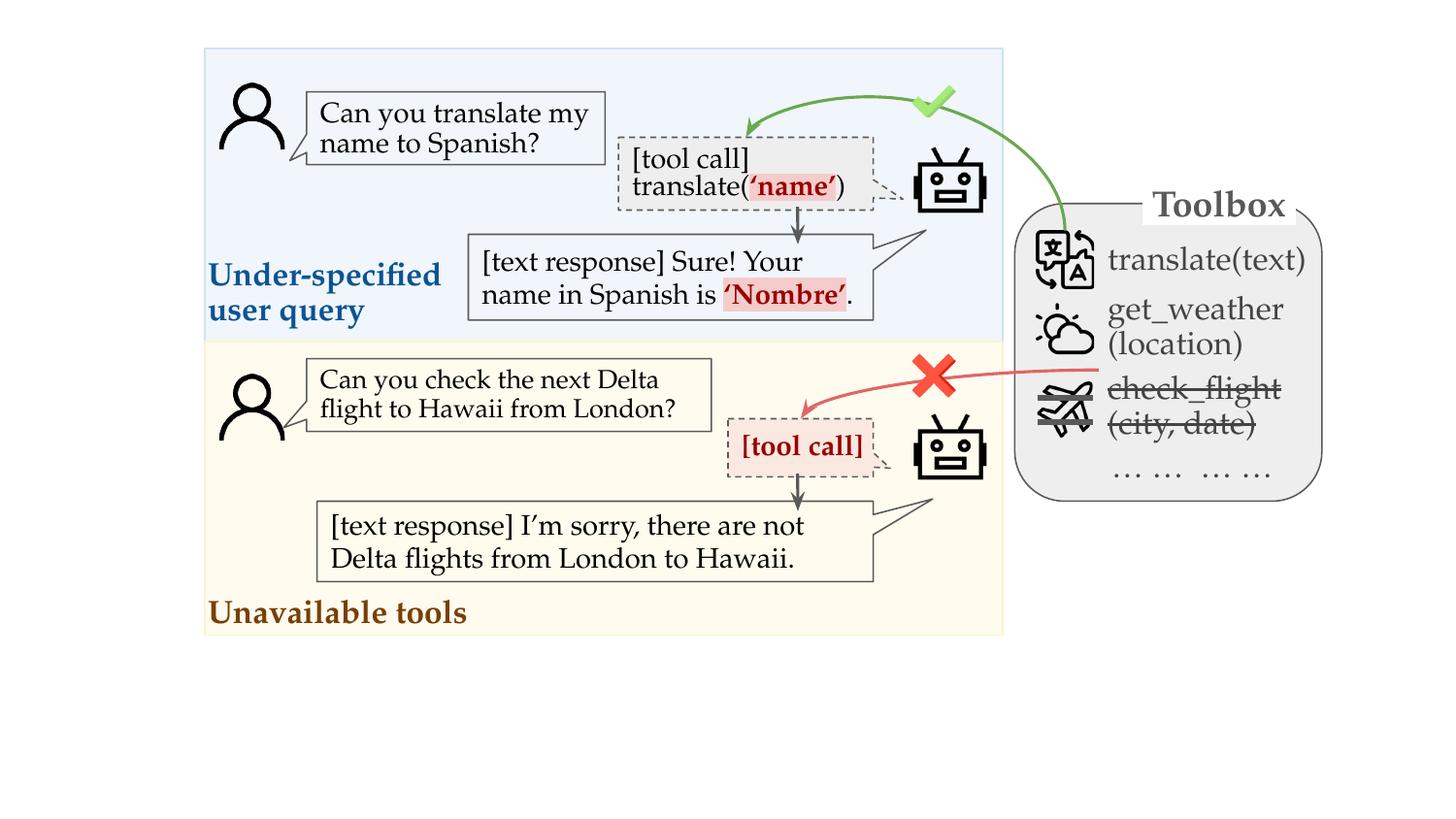
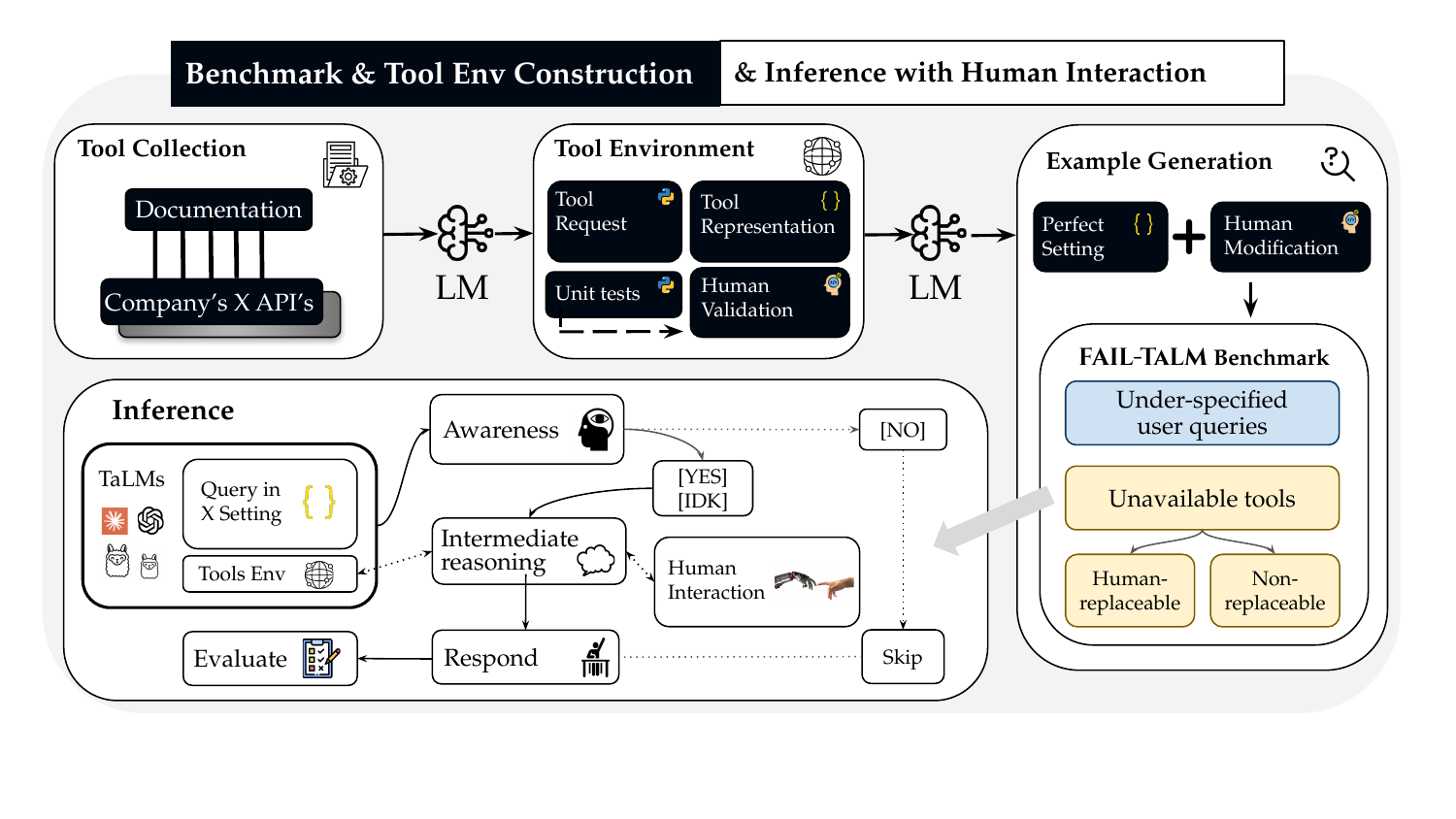
Fail-TaLMs Benchmark Construction
906 real-world tools across 21 categories with execution environments
1,749 total examples: 575 perfect + 599 under-specified + 575 unavailable tools
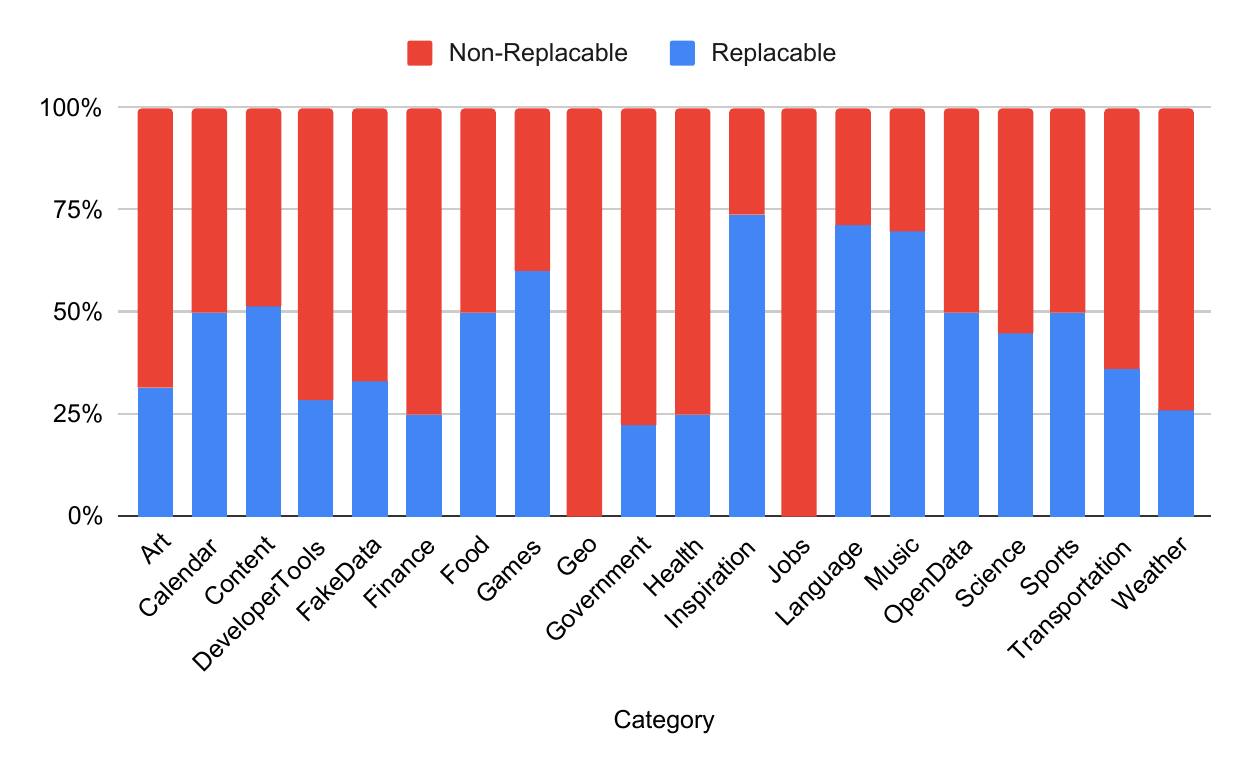
Tool Robustness: Model Performance
Key Finding: Most models struggle to recognize missing information/tools
Claude: 56% awareness rate (best), but awareness ≠ task success
GPT-4o: 4% higher pass rate than Claude despite 44% lower awareness
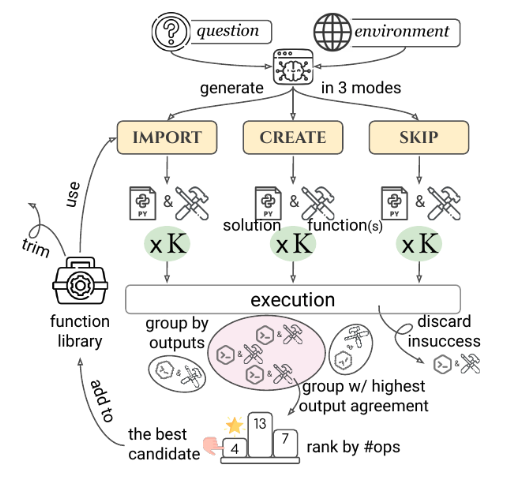
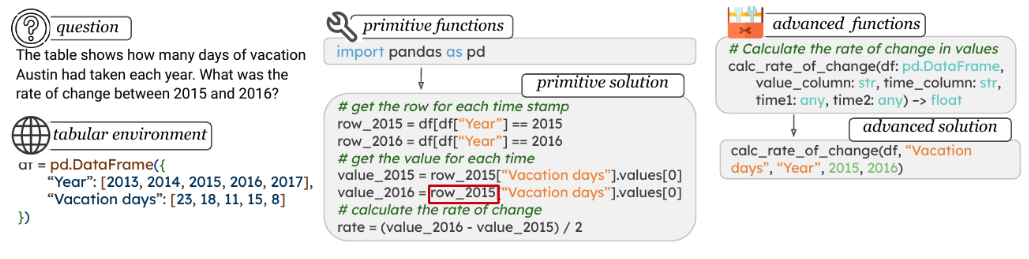
TroVE: Inducing Verifiable and Efficient Toolboxes
Problem: Using primitive functions leads to verbose, error-prone programs
Solution: LMs create reusable high-level functions on-the-fly
TroVE: Primitive vs Advanced Functions
Primitive approach: Complex, error-prone solutions using basic functions
TroVE approach: Concise, accurate solutions using induced functions
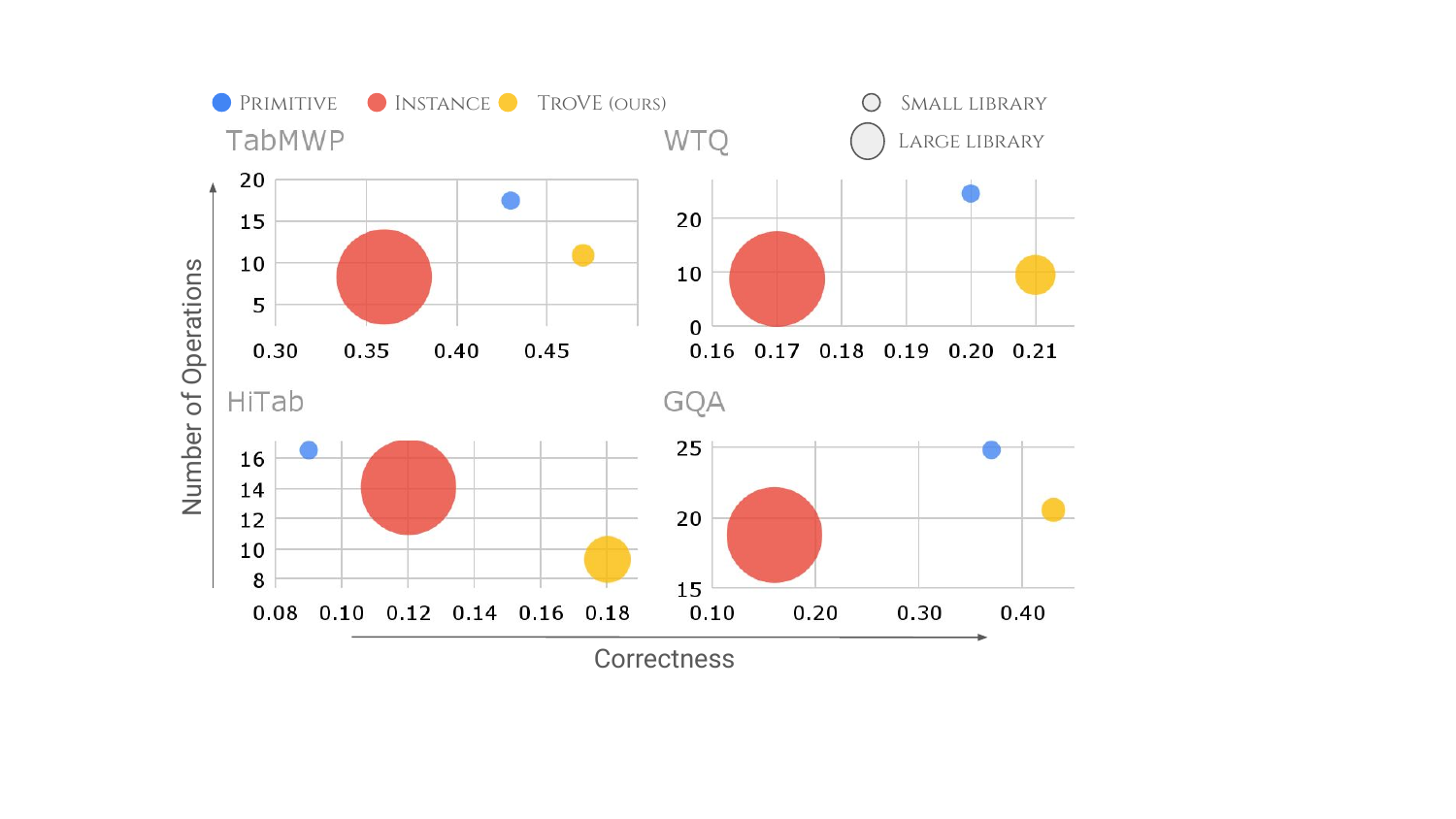
TroVE: Results Across Domains
Math: 30-120% accuracy improvement with simpler solutions
Table QA: Consistent gains with 79-98% smaller toolboxes
Visual: Better performance with reusable visual reasoning functions
Key Takeaways
- Tools enhance LMs by providing external capabilities
- Various paradigms exist: API calls, code execution, function induction
- Training methods include supervised learning, RL, and self-supervision
- Robustness to real-world conditions remains a challenge